
A company I worked with last quarter upgraded their embedding model from a 300M-parameter model to a 1.5B one. Search quality improved. Users noticed. Everyone was happy. Then the VP of Engineering saw the AWS bill three months later. Their vector database costs had tripled, query-time GPU spend had doubled, and nobody could explain when it happened or why.
The embedding layer was the culprit. And nobody had been watching it.
The Cost Nobody's Tracking
Here's the pattern I keep seeing at companies running RAG systems. The team built the search pipeline twelve to eighteen months ago. They picked an embedding model based on a benchmark leaderboard, chunked their documents, stood up a vector database, and moved on to the next feature. The system worked. Nobody touched it again.
Meanwhile, the document corpus grew from one million to ten million. The team upgraded the embedding model for better multilingual support. Maybe they added overlapping chunks to fix a context problem at chunk boundaries. Each decision made sense in isolation. But nobody tracked the compounding infrastructure cost, because most teams don't separate embedding expenses from LLM inference on their cloud bills. The waste hides in plain sight.
Embedding infrastructure used to be a rounding error. The models were small BERT variants, 110M parameters, running on CPUs. Those days are over. Today's best embedding models are 4B parameters, require GPUs, and output high-dimensional vectors that eat RAM when you load them into a search index. If you haven't revisited your embedding layer's cost structure recently, you're almost certainly overpaying.
The good news: three specific techniques can cut that cost by 40-75% with minimal quality impact. None of them require rebuilding your system from scratch.
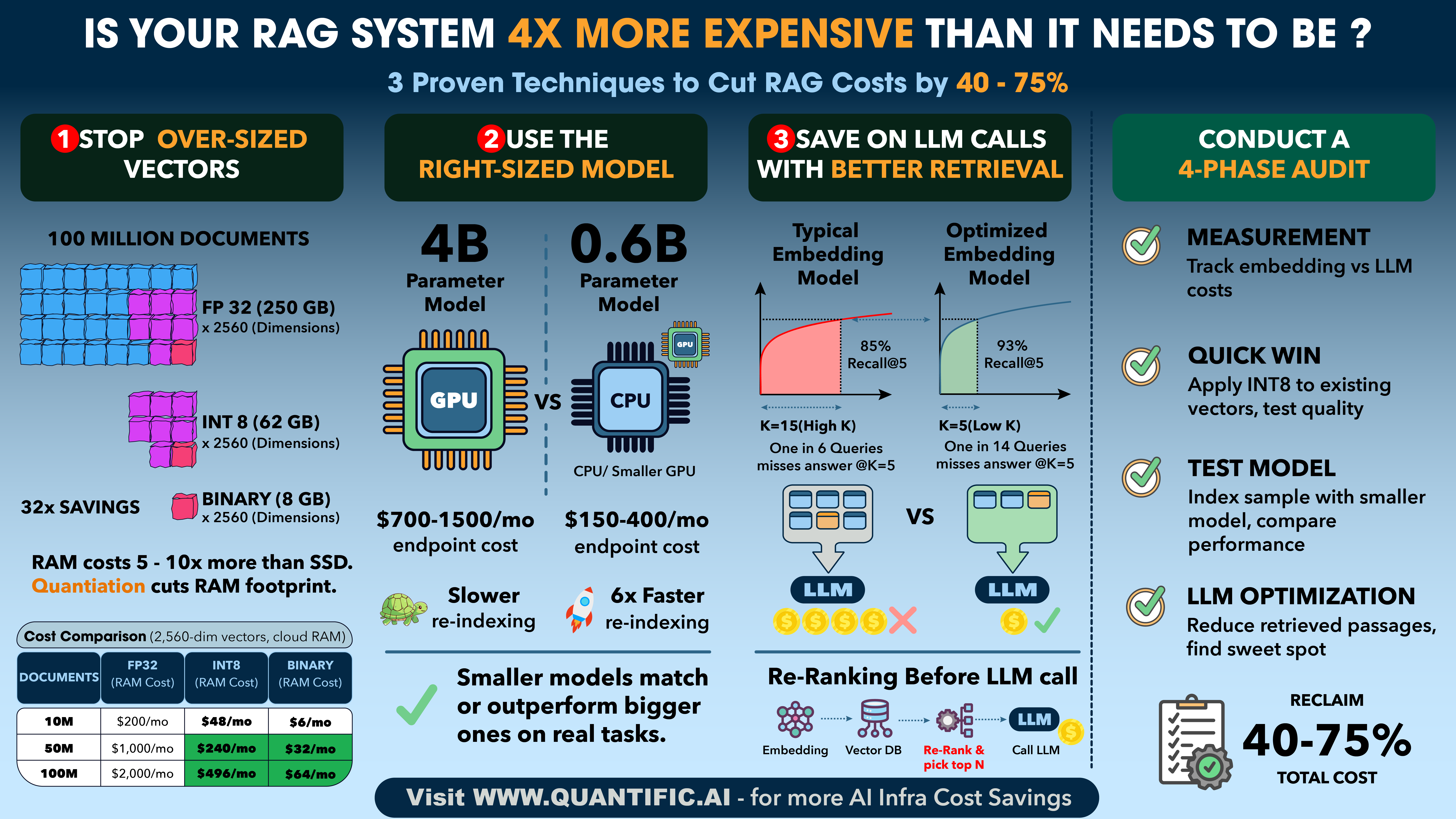
Your Vectors Are 4x Bigger Than They Need to Be
Most embedding models output vectors in 32-bit floating point (FP32). Each dimension of the vector takes 4 bytes. A typical 1,024-dimension embedding is 4 KB per document. At 10 million documents, that's 40 GB just for the vectors. Scale to 100 million and you're at 400 GB.
But the real cost isn't disk storage. It's RAM. Your vector search index, whether it's HNSW or IVF, needs to live in memory for fast retrieval. RAM on cloud instances costs 5-10x more than SSD. That 400 GB index means you're paying for high-memory instances that exist solely to hold vectors in RAM.
Recent advances in quantization-aware training have changed the math. Instead of training a model in full precision and compressing afterward (which degrades quality), newer models train with quantization built into every step of the process. The model learns to produce accurate results at reduced precision from the start. The output: INT8 embeddings, where each dimension takes 1 byte instead of 4. Same quality, one-quarter the size.
Here's what that looks like at scale:
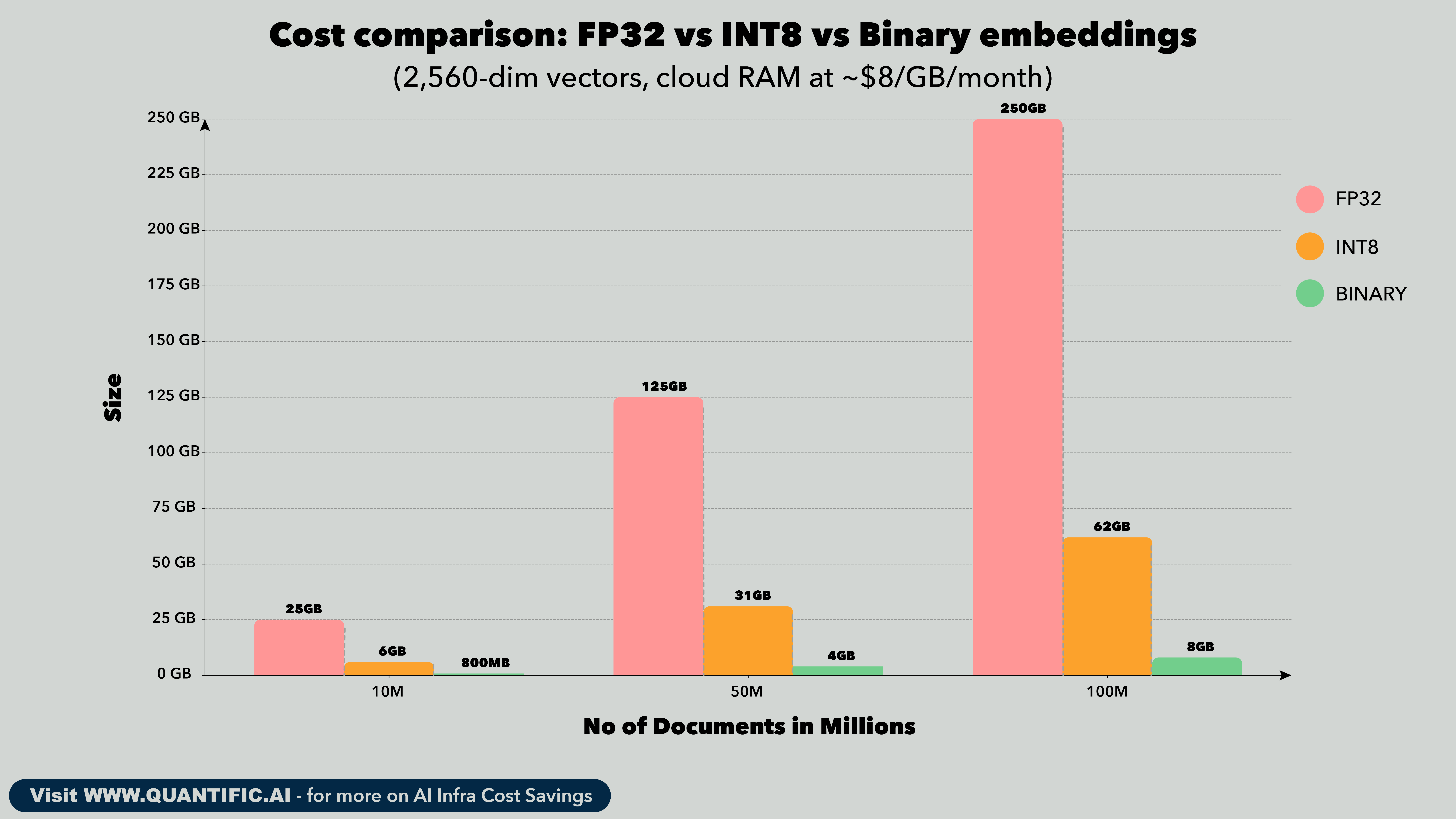
The INT8 column is the straightforward win. Four times less RAM, negligible quality loss when the model is trained for it. But the binary column is where it gets interesting. Binary quantization crushes each dimension to a single bit. The quality does drop, typically 1-3 percentage points on retrieval benchmarks. Used alone, that might be too much. But combined with a two-stage retrieval strategy, it's powerful.
The approach: store both binary and INT8 vectors. Use the binary vectors for a fast first-pass search across your entire corpus. That fits in a fraction of the RAM. Then rescore only the top 1,000 candidates using the full INT8 vectors, which you pull from SSD on demand. You get binary-level infrastructure costs with INT8-level accuracy.
For a 100M document corpus, this means your search index fits in roughly 8 GB of RAM instead of 250 GB. That's the difference between one modest instance and a fleet of high-memory machines.
Your Model Is Probably Too Big
There's been an arms race in embedding model size. The leaderboard logic is simple: bigger model, better benchmark score, ship it. But recent evaluations on real-world retrieval tasks tell a different story. In several large-scale benchmarks testing end-to-end RAG quality, 0.6B-parameter embedding models have matched or outperformed 4B models on three out of five question-answering tasks. The 0.6B models aren't just "close enough." On certain workloads, they're actually better.
This matters for two cost buckets. First, the obvious one: embedding generation. Every time you index or re-index your corpus, you push every document through the model. A 0.6B model runs roughly 6x faster than a 4B model on the same GPU. If you re-index weekly, that's the difference between a 55-minute job and a 5.5-hour job. Multiply by 52 weeks and the compute cost adds up.
Second, and often more expensive: the always-on query embedding endpoint. Every incoming search query needs to be embedded in real time. A 4B model needs a capable GPU, an A10G at minimum, running 24/7. That's $700-1,500 per month just to keep the endpoint warm. A 0.6B model can run on a T4, or for lower-traffic applications, even on CPU. We're talking $150-400 per month.
The catch is that public benchmarks don't reliably predict which model works best for your specific data. I've seen cases where a smaller model outperforms a larger one on a company's actual queries, and cases where the opposite is true. The only way to know is to test on your own traffic. Take 1,000 real queries from your logs, retrieve top-10 documents with both models, and evaluate which results are better. If the smaller model is comparable, you've just found a 4-6x savings on embedding compute.
Better Retrieval Means Cheaper LLM Calls
This is the savings most teams miss entirely because it lives in a different line item on the cloud bill.
Here's the mechanism. Every RAG system retrieves top-K passages and feeds them to the LLM as context. The number K is usually set during the initial build and never revisited. Most teams pick a high K (10, 15, sometimes 20) as insurance. The reasoning: "if our retrieval misses the relevant passage at top-5, maybe it shows up at position 8 or 12." That reasoning is correct when retrieval quality is poor. But it's expensive insurance, and better retrieval eliminates the need for it.
The metric that drives this decision is Recall@K: what fraction of relevant documents appear in the top K results? When your embedding model achieves 85% Recall@5, one in six queries fails to surface the answer in the top 5 passages. So you bump K to 10 or 15 to compensate. But a model that achieves 93% Recall@5 means you can confidently serve top-5 and only miss on one in fourteen queries. That gap between 85% and 93% is worth real money.
The direct token cost
Each retrieved passage adds 150-250 tokens to the LLM prompt. A system prompt and query template add another 100-200 tokens of overhead. The arithmetic scales linearly with K.
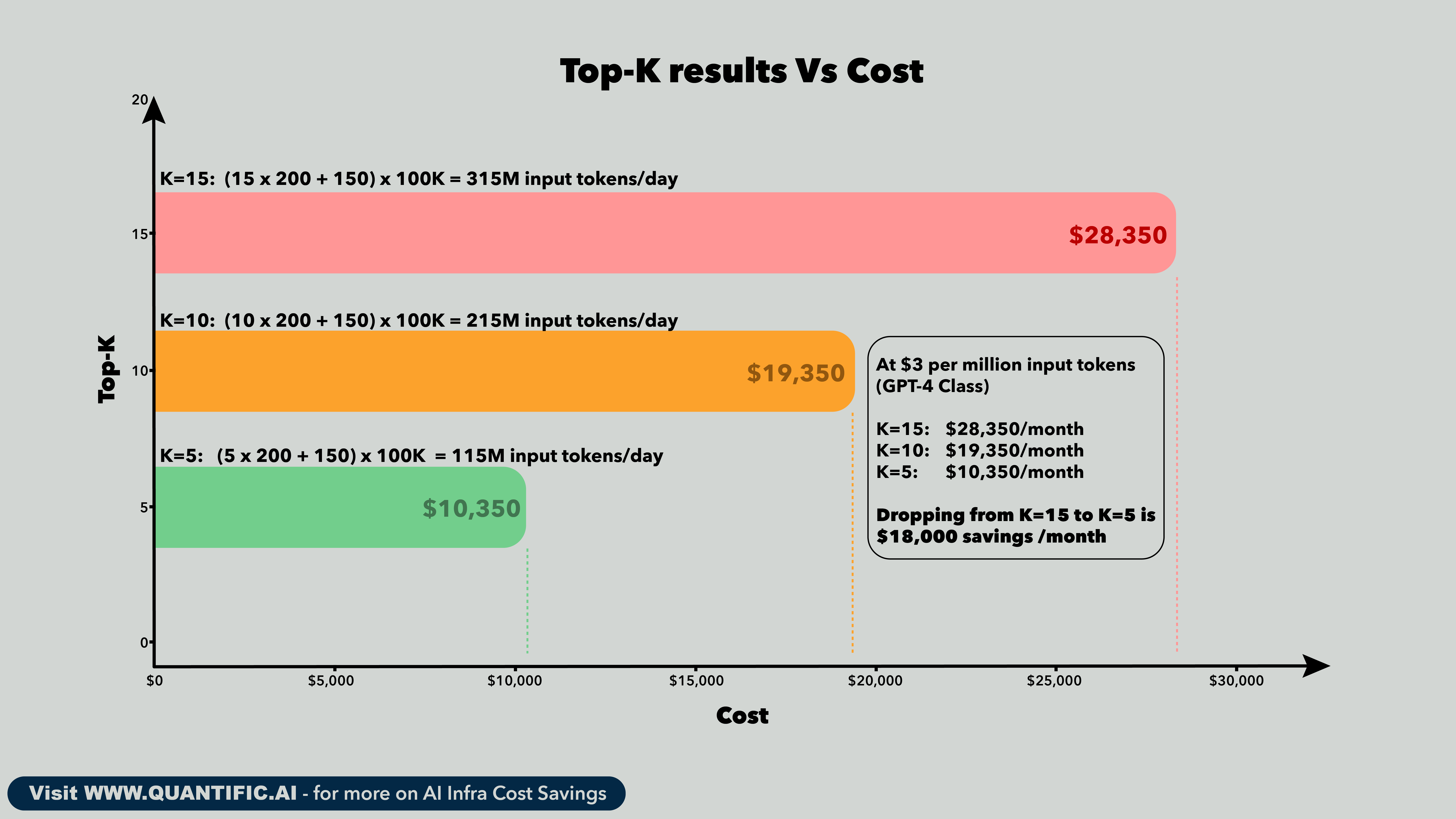
That's $216,000 per year from changing one integer in your retrieval config. The prerequisite is retrieval quality high enough to justify the lower K.
The noise problem is worse than the token problem
Raw token cost is only part of the story. The bigger issue is that irrelevant passages in the context window actively degrade the LLM's output quality.
Research on "lost in the middle" effects shows that LLMs pay disproportionate attention to passages at the beginning and end of the context, while information buried in the middle gets partially ignored. When you retrieve 15 passages and only 3 are relevant, the LLM is wading through 12 passages of noise to find the signal. The relevant passage might land at position 7 or 8 in the context, right in the dead zone. The LLM either misses it, gives it less weight, or worse, gets confused by a partially relevant but misleading passage that happens to sit at position 1 or 2.
I've seen this produce a counterintuitive result during infrastructure reviews. A team reduced K from 12 to 5 after upgrading their embedding model, expecting roughly equal answer quality. Instead, answer quality went up. The LLM wasn't distracted by marginally relevant passages anymore. Every passage in the context was pulling its weight.
This has a direct cost implication beyond token pricing. When the LLM generates a bad answer because of context pollution, the user retries. That retry is another full RAG cycle: another embedding call, another vector search, another set of LLM tokens. At scale, poor retrieval quality creates a retry rate that inflates the effective cost of every component in the pipeline.
The latency and throughput multiplier
LLM inference time scales with prompt length. For transformer-based models, the prefill phase (processing all input tokens before generating the first output token) is roughly linear in input length for most practical context sizes. Cutting input tokens from 3,150 to 1,150 per query doesn't just save money. It cuts time-to-first-token by approximately 40-60%.
That latency improvement has a throughput consequence. If you're serving LLM requests on a fixed GPU fleet, faster prefill means each GPU can serve more requests per second. For a team running four A100s at 80% utilization with K=15, dropping to K=5 could let them serve the same traffic on two or three A100s. At $2-4 per A100-hour, that's another $1,500-3,000 per month in GPU savings that doesn't show up in the token cost calculation.
The reranking shortcut
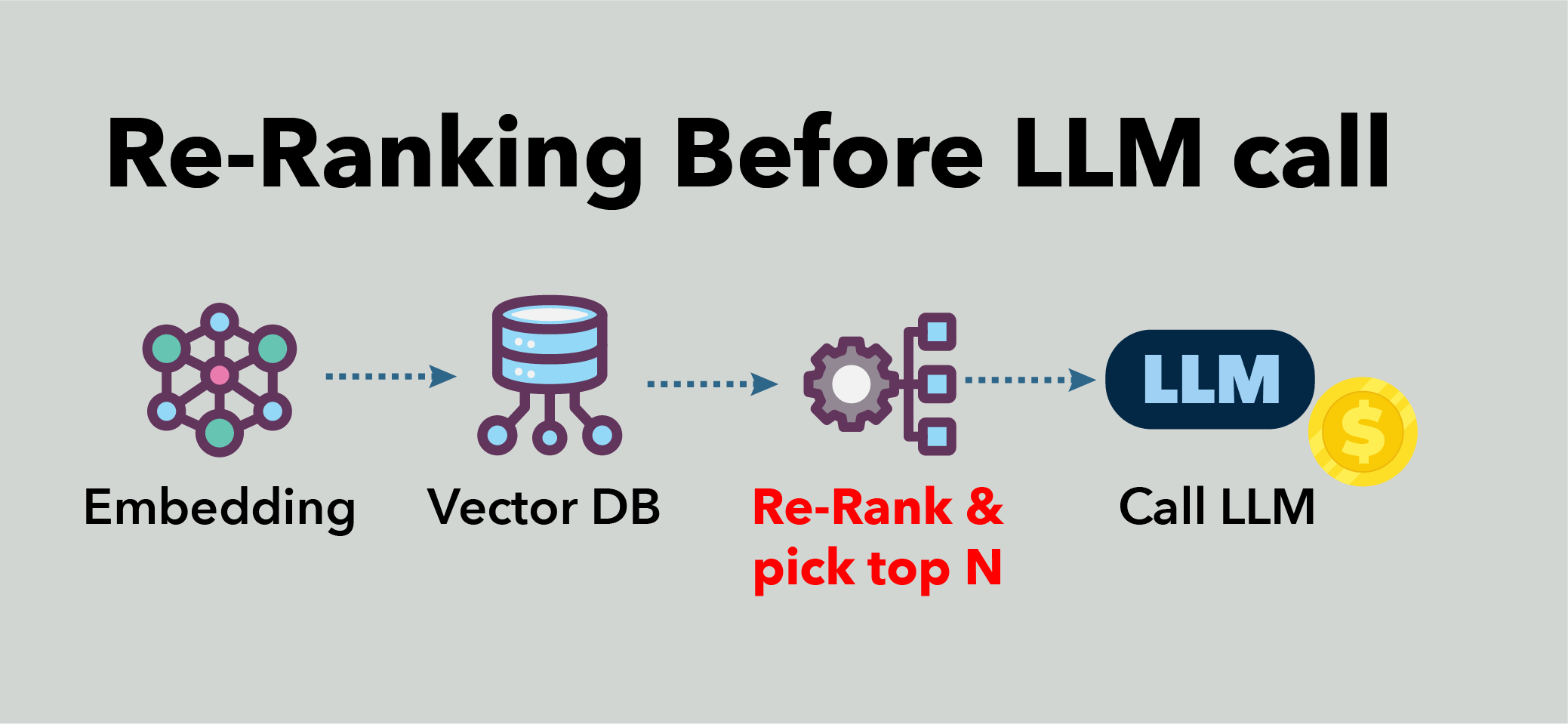
There's an intermediate option that teams often overlook. Instead of reducing K directly, retrieve a larger candidate set (say K=20) and then run a lightweight reranker (a cross-encoder model) to re-score and pick the top 5. Cross-encoders are more accurate than embedding models at scoring query-passage pairs because they process both texts jointly instead of independently. But they're too slow to run against your entire corpus. The trick is to use the embedding model to cast a wide net cheaply, then use the reranker to select precisely.
The combined cost of embedding retrieval at K=20 plus reranking to top-5 is typically less than the cost of feeding all 20 passages to the LLM. A small cross-encoder (150M parameters) running on a T4 can score 20 candidates in under 10 milliseconds. That's $150-300 per month for the reranking endpoint. Compare that to the $18,000/month difference between K=15 and K=5 in LLM tokens. The reranker pays for itself fifty times over.
When I audit RAG infrastructure costs, this retrieval-to-generation cost link is often the single largest optimization available. It shows up on the LLM bill, not the embedding bill, which is exactly why nobody connects the two. The team optimizing LLM costs looks at model selection and prompt engineering. The team managing retrieval looks at index performance and query latency. Nobody is measuring how retrieval quality flows through to generation cost. That gap is where the savings hide.
The Four-Phase Audit
None of this requires a risky migration or a system rewrite. Here's a low-risk path to test and capture these savings.
Phase 1 is measurement. Separate your embedding costs from your LLM costs. How much RAM does your vector index consume? What GPU is running your query embedding endpoint? How often do you re-index? How many passages do you retrieve per query? Most teams can't answer these questions without digging, which is the first sign of hidden waste.
Phase 2 is the quick win. Apply INT8 quantization to your existing vectors. Many vector databases support this natively. Run your standard evaluation queries and compare retrieval quality before and after. If the quality holds, you've just cut your vector storage costs by 75% with a configuration change.
Phase 3 is the model test. Index a sample of your corpus with a smaller or newer embedding model. Compare retrieval quality head-to-head on real queries, not benchmarks. If the smaller model is comparable, plan the migration and capture the compute savings on both indexing and query-time inference.
Phase 4 is the LLM optimization. With better retrieval in place, test reducing the number of retrieved passages. Drop from 10 to 7, then to 5. Measure answer quality at each step. Find the point where quality is maintained and lock in the token savings.
A conservative run through this playbook typically surfaces 40-75% total cost reduction across the RAG stack. I've seen teams save $15K-40K per month at the 50-100M document scale.
Where the Savings Are Hiding
The embedding layer is the most under-optimized component in most RAG systems. It was configured once during the initial build, and engineering effort since then has gone to the LLM, the UI, the product features. Meanwhile, the corpus grew, the model got upgraded, and nobody recalculated the infrastructure requirements.
That's where the money is. Not just in the flashy LLM serving costs that everyone monitors, but in the quiet, compounding expense of storing and searching billions of vectors that are four times larger than they need to be, on GPUs that are four times more powerful than necessary, retrieving four times more context than the LLM actually needs.
The techniques exist today. The math is straightforward. The risk is low. The only question is whether anyone on your team is looking.
References
If this was useful, follow me for weekly insights on AI infrastructure efficiency. And if you're a Series B+ company spending $50K+/month on AI compute and suspect your RAG infrastructure has room to trim, DM me. I'll give you a quick read on where your biggest savings likely are.